More=Better?
In this post I want to share a few quick experiments to show something that is both obvious and also perhaps underappreciated: you can get a sizeable quality boost from a generative model by generating MORE. For example, generating more samples and picking the best ones (with a few caveats). I’ll show this in action and talk about some of the implications.
Pic The Best
Let’s start on images. Imagine you have two competing text-to-image systems. Both use an identical model, but when A generates an image it only generates and shows one sample, while B generates 4 and picks the best one. What percentage of the time will you prefer the image from B? 80% of the time! Newer models are lucky if they can brag about a 5% improvement in win-rate over the competition (see below) so an 80% win rate is huge. Now do the maths for a case where we generate 100 images and pick the best…

Of course, there’s a catch. “The best one” in the previous paragraph assumed we have a way of picking in advance which of the four you’ll prefer. Imagine instead that B generates 4 images and returns one of the four at random. Now the win-rate is back to 50%. And worse, it takes 4x as long! So the only way our scheme has any legs is if we can somehow pick images in a way that at least roughly aligns with what humans (you’re a human right?) will prefer.
One useful measure is the CLIP similarity score between the image and the prompt, which tends to track well with how accurately the image represents the prompt. CLIP was used to pick the best images out of 256 candidates in the original DALL-E text-to-image system! Another option is to use a model trained to predict human ratings or preferences - I’m a fan of PickScore which correlates well with aesthetics in my experience.


Results from a test with the prompt “An astronaut riding a horse on mars”. CLIP helps us pick images that better match the prompt.
Now, how can we spend even more inference time compute to get this system to deliver even better results? We have big LLMs now that can do things like re-write the prompt, and since some are ‘multimodal’ we can also show them the results and use that to modify the prompt to fix any potential flaws. With this we’re moving from ‘generate N pick one’ to something more like the ‘flow engineering’ the cool kids like to talk about, creating multi-step processes that refine the result. Think about something like this:
Your task is to evaluate whether the following image accurately follows the prompt.
Prompt: {image_prompt}
If the image follows the prompt well, respond with 'yes'.
If not, suggest a better prompt...This notebook shows the first step (using PickScore and CLIP to rank images) - I leave it to your imagination to take it from there!
Text
How can we map similar ideas to text? As a first test I was curious how well best-of-N would work for text generation. With AlpacaEval-2 as the metric, let’s see how much we can boost Llama 3 8B. I used this reward model (which itself is also a fine-tune of Llama 3 8B, making this something we could reasonably imigine being a lightweigt adapter) to score the candidate completions. Best-of-10 vs the baseline boost the win rate from 20.5% to 29.0%. Not bad! (Here is a notebook showing my approach if you’re curious about the details.)
| Model | win_rate | avg_length |
|---|---|---|
| gpt4_turbo | 50.0 | 2049 |
| Yi-34B-Chat | 29.7 | 2123 |
| Llama 3 8B (Best of 10) | 29.0 | 1895 |
| gpt4 | 23.6 | 1365 |
| mistral-medium | 21.9 | 1500 |
| Llama 3 8B (Default) | 20.5 | 1795 |
| Mixtral-8x7B-Instruct-v0.1 | 18.3 | 1465 |
| claude-2 | 17.2 | 1069 |
| gemini-pro | 16.8 | 1315 |
| tulu-2-dpo-70b | 16.0 | 1418 |
| claude-2.1 | 15.7 | 1096 |
| Mistral-7B-Instruct-v0.2 | 14.7 | 1676 |
| llama-2-70b-chat-hf | 13.9 | 1790 |
| llama-2-13b-chat-hf | 7.7 | 1513 |
| llama-2-7b-chat-hf | 5.0 | 1479 |
| text_davinci_001 | 2.8 | 296 |
I’m not the first to think of this approach - looking at the full leaderboard reveals a number of entries with names like Snorkel (Mistral-PairRM-DPO+best-of-16) which have obviously taken a similar approach. With LLM-judged leaderboards like this we must always be cautious translating scores to true performance… Which brings up a good, more general question: how should we rank/score outputs if we want to bring this same approach to bear on other text generation tasks? And how can we improve on the simple ‘best of N’ approach?
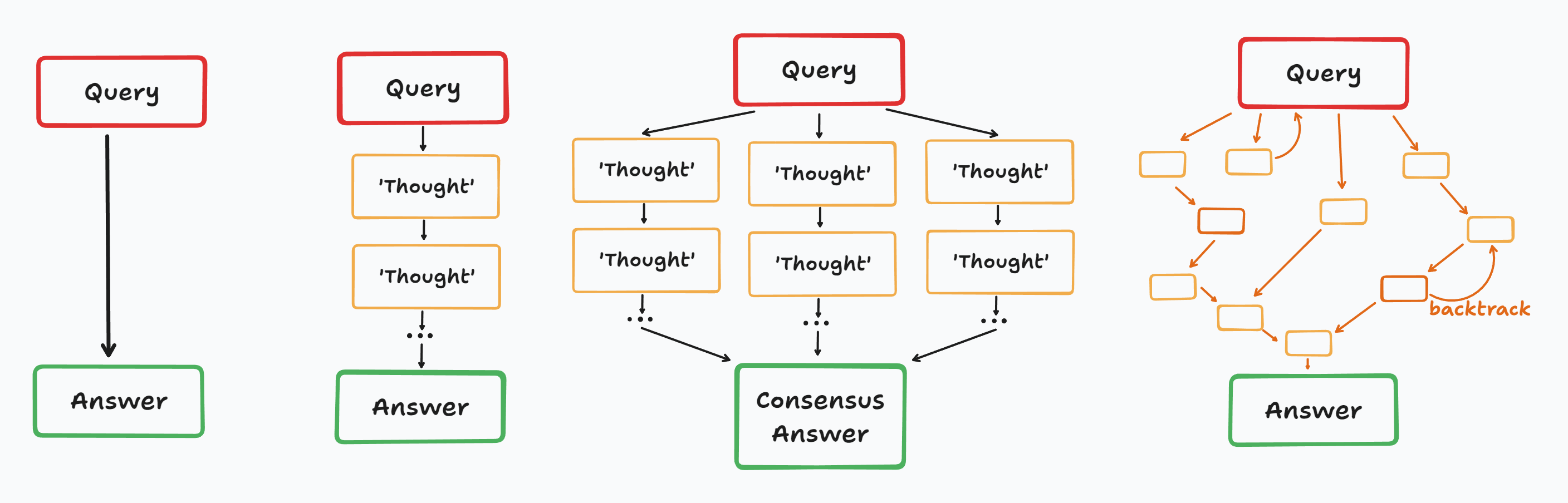
The literature around this topic is filling up with approaches, some of which are illustrated in the figure above. There’s ‘Chain of Thought’ where we ask the model to produce some intermediate reasoning steps before its final answer, ‘Tree of Thought’ which constructs a tree of possible completions, along with tons of variations that cajole different models into debates with eachother, introduce ‘backtracking’ to try and correct mistakes partway through, and so on.
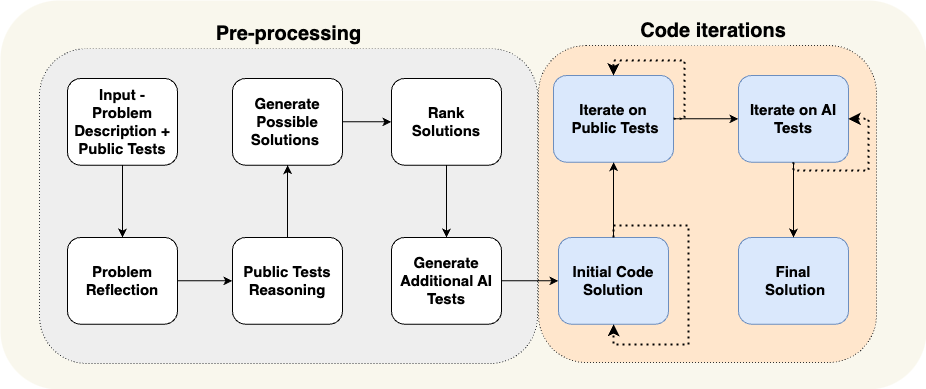
The code generation ‘flow’ from Alphacodium is a good example of a complex flow tuned to a specific system. Unlike our reward model example, they use tests (both existing tests and ones they generate) to select from multiple candidate solutions for programming questions. I’d like to collect more examples like this - if you spot one in the wild please ping me on X!
Conclusions
So there we have it, a few examples of how MORE can lead to BETTER. There are many more directions you could take things: - Applying similar ideas to training (for example, generating samples then picking the best to finetune with)
Exploring more complex approaches to searching the space of possible completions (the mythical Q* anyone?)
Finding ways to dynamically allocate more compute for ‘difficult’ tokens (for example, Mixture of Depths
Coming up with new ways to quantify what ‘good’ means in specific domains
There’s a point of view that spending this time to get more out of existing models like this is futile in the face of the next big one (TM) which will do even better without any tricks. I don’t buy it! As we get faster, cheaper, better models, I believe that finding ways to boost them even further will continue to be worth it. I hope this post inspires you to explore this too :)