gpu.cpp: portable GPU compute for C++ with WebGPU
We’re thrilled to announce the release of gpu.cpp. gpu.cpp is a lightweight, open-source library that makes portable GPU compute with C++ simple.
gpu.cpp focuses on general purpose native GPU computation, leveraging the WebGPU specification as a portable low-level GPU interface. This means we can drop in GPU code in C++ projects and have it run on Nvidia, Intel, AMD, and other GPUs. The same C++ code can work on a wide variety of laptops, workstations, mobile devices or virtually any hardware with Vulkan, Metal, or DirectX support.
The project is located at github.com/AnswerDotAI/gpu.cpp.
Use Cases
gpu.cpp is aimed at enabling projects requiring portable on-device GPU computation with minimal implementation complexity and friction. Some example use cases are:
- Development of GPU algorithms to be run on personal computing devices
- Direct standalone implementations of neural network models
- Physics simulations and simulation environments
- Multimodal applications - audio and video processing
- Offline graphics rendering
- ML inference engines and runtimes
- Parallel compute intensive data processing applications
Although gpu.cpp is meant for any general purpose GPU computation and not strictly AI, one area we’re interested in is pushing the limits exploring the intersection of new algorithms for post-training and on-device compute.
To date, AI research has primarily been built with CUDA as the priveledged first-class target. CUDA has been dominant at large scale training and inference but at the other end of the the spectrum in the world of GPU compute on personal devices, there exists far more heterogeneity in the hardware and software stack.
GPU compute in this personal device ecosystem has been largely limited to a small group of experts such as game engine developers and engineers working directly on ML compilers or inference runtimes. Along with that, implementing against the Vulkan or even WebGPU API directly tends to be targeted mostly towards infrastrcture scale efforts - game engines, production ML inference engines, large software packages.
We want to make it easier for a broader range of projects to harness the power of GPUs on personal devices. With a small amount of code, we can access the GPU at a low-level, focusing on directly implementing algorithms rather than the scaffolding and tech stack around the GPU. For example, in our AI research there’s much to explore with the various forms of dynamic/conditional post-training computation - dynamic use of adapters, sparsity, model compression, realtime multimodal integrations etc.
gpu.cpp lets us implement and drop-in any algorithm with fine-grained control of data movement and GPU code, and explore outside boundaries of what is supported by existing production-oriented inference runtimes. At the same time we can write code that is portable and immediately usable on a wide variety of and GPU vendors and compute form factors - workstations, laptops, mobile, or even emerging hardware platforms such as AR/VR and robotics.
Technical Objectives: Lightweight, Fast Iteration, and Low Boilerplate
With gpu.cpp we want to enable a high-leverage library for individual developers and researchers to incorporate GPU computation into programs relying on nothing more than a standard C++ compiler as tooling. Our goals are:
- High power-to-weight ratio API: Provide the smallest API surface area that can cover the full range of GPU compute needs.
- Fast compile/run cycles: Ensure projects can build nearly instantaneously, compile/run cycles should be <5 seconds on a modern laptop.
- Minimal dependencies and tooling overhead: A standard clang C++ compiler should be enough, no external library dependencies beyond the WebGPU native implementation.
The implementation aims for a small API surface area with minimum boilerplate. There are a small number (about a dozen) of library operations to carry out an broad range of low-level GPU operations. We avoid abstractions that add layers of indirection, making the mapping between the gpu.cpp library to raw WebGPU API clear when it’s needed.
In this spirit of lightweight experimentation, we also want fast iteration - instantaneous C++ builds taking no more than a second or two even on modestly capable personal computing devices. With this in mind, we not only keep the API surface area small, but also keep the implementation small and we also provide a prebuilt binary of the Dawn native WebGPU implementation.
The core library implementation in the header-only gpu.h source code is around 1000 lines of code. In addition to enabling instantaneous, semi-interactive compilation cycles, the small implementation surface area keeps maintenance burden low and the velocity of improvements high. We also pre-build Google’s Dawn WebGPU implementation as a shared library binary. This allows builds to link the shared library with each build and incorporate Google’s powerful native WebGPU implementation without paying the cost of re-compiling Dawn during development cycles. For more advanced users and release deployments, we include cmake examples for building both Dawn with gpu.cpp end-to-end.
Hello World: A GELU Kernel
As a real-world example for how to use gpu.cpp, let’s start with a practical-but-simple example of a GPU kernel from neural networks.
GELU is a non-linear embarassingly parallel operation often used in modern large language model transformer-based architectures.
It takes as input a vector of floats and applies the GELU function to each element of the vector. The function is nonlinear, attenuating values below zero to near zero, approximating the y = x identity function for large positive values. For values close to zero, GELU smoothly interpolates between the identity function and the zero function.
The GELU code below will illustrate the three main aspects of setting up a GPU computation with gpu.cpp:
The code that runs on the GPU (in WebGPU Shading Language, or WGSL), implementing the compute opporation.
The code that runs on the CPU (in C++) that sets up the GPU computation by allocating and preparing resources. For high performance, this code should be run ahead-of-time from the hot paths of the application.
The code that runs on the CPU (in C++) that dispatches the GPU computation and retrieves the results. The key concern of hot-path dispatch code is to eliminate or minimize any unnecessary resource allocation or data movement (offloading such concerns to step 2). A secondary consideration is that GPU dispatches are asynchronous. We work with standard C++ asynchronous primitives to manage the asynchronous aspect of kernel dispatch.
Here’s a GELU kernel implemented (based on the CUDA implementation in llm.c) as on-device WebGPU WGSL code and invoked from the host using gpu.cpp library functions and types. It can be compiled using a standard C++ compiler (we recommend Clang):
#include <array>
#include <cstdio>
#include <future>
#include "gpu.h"
using namespace gpu; // createContext, createTensor, createKernel,
// dispatchKernel, wait, toCPU Bindings,
// Tensor, Kernel, Context, Shape, kf32
static const char *kGelu = R"(
const GELU_SCALING_FACTOR: f32 = 0.7978845608028654; // sqrt(2.0 / PI)
@group(0) @binding(0) var<storage, read_write> inp: array<{{precision}}>;
@group(0) @binding(1) var<storage, read_write> out: array<{{precision}}>;
@compute @workgroup_size({{workgroupSize}})
fn main(
@builtin(global_invocation_id) GlobalInvocationID: vec3<u32>) {
let i: u32 = GlobalInvocationID.x;
if (i < arrayLength(&inp)) {
let x: f32 = inp[i];
out[i] = select(0.5 * x * (1.0 + tanh(GELU_SCALING_FACTOR
* (x + .044715 * x * x * x))), x, x > 10.0);
}
}
)";
int main(int argc, char **argv) {
Context ctx = createContext();
static constexpr size_t N = 10000;
std::array<float, N> inputArr, outputArr;
for (int i = 0; i < N; ++i) {
inputArr[i] = static_cast<float>(i) / 10.0; // dummy input data
}
Tensor input = createTensor(ctx, Shape{N}, kf32, inputArr.data());
Tensor output = createTensor(ctx, Shape{N}, kf32);
std::promise<void> promise;
std::future<void> future = promise.get_future();
Kernel op = createKernel(ctx, {kGelu, /* 1-D workgroup size */ 256, kf32},
Bindings{input, output},
/* number of workgroups */ {cdiv(N, 256), 1, 1});
dispatchKernel(ctx, op, promise);
wait(ctx, future);
toCPU(ctx, output, outputArr.data(), sizeof(outputArr));
for (int i = 0; i < 16; ++i) {
printf(" gelu(%.2f) = %.2f\n", inputArr[i], outputArr[i]);
}
return 0;
}Here we see the GPU code is quoted in a domain specific language called WGSL (WebGPU Shading Language). In a larger project, you might store this code in a separate file to be loaded at runtime (see examples/shadertui for a demonstration of live WGSL code re-loading).
The CPU code in main() sets up the host coordination for the GPU computation. We can think of the use of gpu.cpp library as a collection of GPU nouns and verbs.
The “nouns” are GPU resources modeled by the type definitions of the library and the “verbs” actions on GPU resources, modeled by the functions of the library. The ahead-of-time resource acquisition functions are prefaced with create*, such as:
createContext()- constructs a reference to the GPU device context (Context).createTensor()- acquires a contiguous buffer on the GPU (Tensor).createKernel()- constructs a handle to resources for the GPU computation (Kernel), taking the WGSL code as input and the tensor resources to bind.
These resource acquisition functions are tied to resource types for interacting with the GPU:
Context- a handle to the state of resources for interacting with the GPU device.Tensor- a buffer of data on the GPU.KernelCode- the code for a WGSL program that can be dispatched to the GPU. This is a thin wrapper around a WGSL string and also includes the workgroup size the code is designed to run with.Kernel- a GPU program that can be dispatched to the GPU. This accepts aKernelCodeand a list ofTensorresources to bind for the dispatch computation. This takes an argumentBindingsthat is a list ofTensorinstances and should map the bindings declared at the top of the WGSL code. In this example there’s two bindings corresponding to theinputbuffer on the GPU and theouptutbuffer on the GPU.
In this example, the GELU computation is performed only once and the program immediately exits so preparing resources and dispatch are side-by-side. Other examples in the examples/ directory illustrate how resource acquisition is prepared ahead of time and dispatch occurs in the hot path like a render, model inference, or simulation loop.
Besides the create* resource acquisition functions, there are a few more “verbs” in the gpu.cpp library for handling dispatching execution to the GPU and data movement:
dispatchKernel()- dispatches aKernelto the GPU for computation. This is an asynchronous operation that returns immediately.wait()- blocks until the GPU computation is complete. This is a standard C++ future/promise pattern.toCPU()- moves data from the GPU to the CPU. This is a synchronous operation that blocks until the data is copied.toGPU()- moves data from the CPU to the GPU. This is a synchronous operation that blocks until the data is copied. In this particular example,toGPU()is not used because there’s only one data movement from CPU to GPU in the program and that happens when thecreateTensor()function is called.
This example is available in examples/hello_world/run.cpp.
Building: Clang is (Almost) All You Need
To build a gpu.cpp project, you will need to have installed on your system:
clang++compiler installed with support for C++17.python3and above, to run the script which downloads the Dawn shared library. make to build the project.maketo build the project.- Only on Linux systems - Vulkan drivers. If Vulkan is not installed, you can run
sudo apt install libvulkan1 mesa-vulkan-drivers vulkan-toolsto install them.
The only library dependency of gpu.cpp is a WebGPU implementation. Currently we support the Dawn native backend, but we plan to support other targets and WebGPU implementations (web browsers or other native implementations such as wgpu). Currently we support MacOS, Linux, and Windows (via WSL).
Optionally, Dawn can be built from scratch with gpu.cpp using the cmake build scripts provided - see the -cmake targets in the Makefile. However, this is recommended for advanced users only. Building Dawn dependencies with cmake takes much longer than using the precompiled Dawn shared library.
After cloning the repo, from the top-level gpu.cpp, you should be able to build and run the hello world GELU example by typing:
makeThe first time you build and run the project this way, it will download a prebuilt shared library for the Dawn native WebGPU implementation automatically (using the setup.py script). This places the Dawn shared library in the third_party/lib directory. Afterwards you should see libdawn.dylib on MacOS or libdawn.so on Linux. This download only occurs once.
The build process itself should take a few seconds. If the build and executions is successful, you should see the output of the GELU computation:
Hello gpu.cpp!
--------------
gelu(0.00) = 0.00
gelu(0.10) = 0.05
gelu(0.20) = 0.12
gelu(0.30) = 0.19
gelu(0.40) = 0.26
gelu(0.50) = 0.35
gelu(0.60) = 0.44
gelu(0.70) = 0.53
gelu(0.80) = 0.63
gelu(0.90) = 0.73
gelu(1.00) = 0.84
gelu(1.10) = 0.95
gelu(1.20) = 1.06
gelu(1.30) = 1.17
gelu(1.40) = 1.29
gelu(1.50) = 1.40
...
Computed 10000 values of GELU(x)Other Examples: Matrix Multiplication, Physics Sim, and SDF Rendering
You can explore the example projects in examples/ which illustrate how to use gpu.cpp as a library.
Assuming you’ve already run make in the top-level directory which retrieves the prebuilt Dawn shared library, you can run each example by navigating to its directory and running make from the example’s directory.
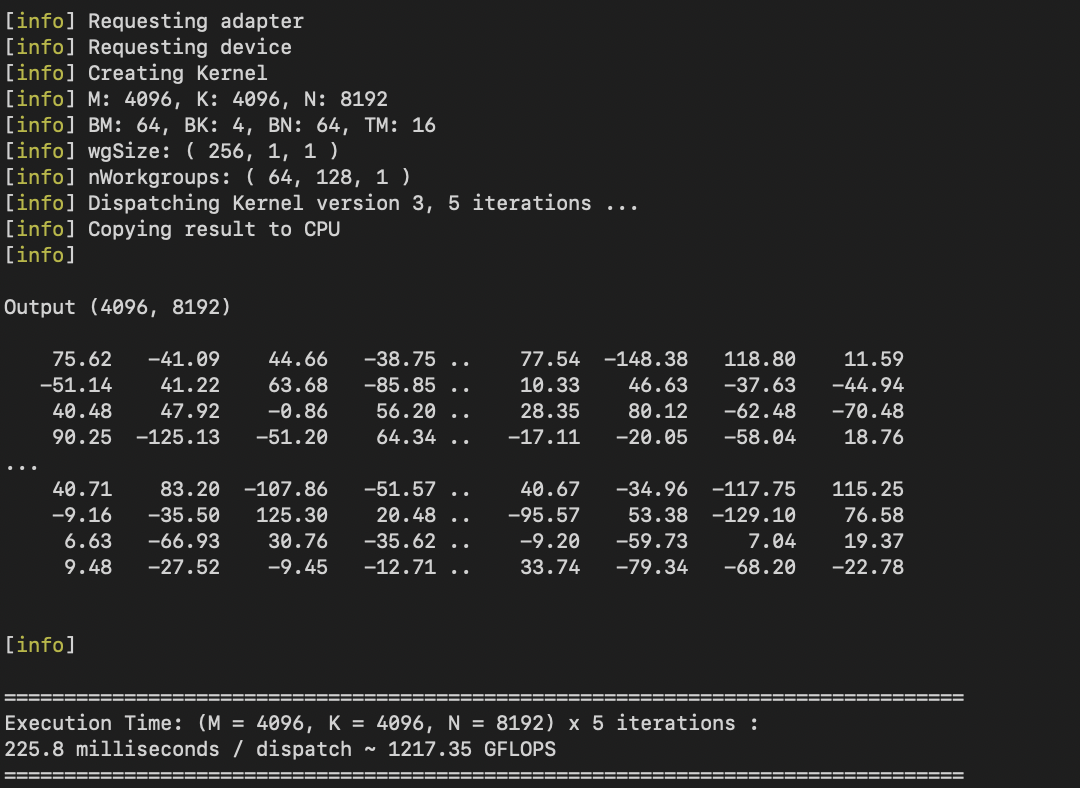
An example of tiled matrix multiplication is shown in examples/matmul. This implements a WebGPU version of the first few kernels of Simon Boehm’s now-famous How to Opitmize a CUDA Matmul Kernel for cuBLAS-like Performance: a Worklog post. It is only weakly optimized (up to 1D blocktiling, kernel number 4), but nonetheless already achieves an estimated ~ 1.2+ TFLOPs on a Macbook Pro M1 laptop, which has a theoretical peak of 10.4 TFLOPs. Contributions to optimize this further are welcome - kernels 5-9 of Simon’s post would be a natural starting point.
A parallel physics simulation of N double pendulums running simultaneously on the GPU is shown in examples/physics.

We also show some examples of signed distance function computations, rendered in the terminal as ascii. A 3D SDF of spheres is shown in examples/render and a shadertoy-like live-reloading example is in examples/shadertui. Interestingly, with a starting example, LLMs such as Claude 3.5 Sonnet can be quite capable at writing low-level WGSL code for you - the other shaders in the shadertui example are written by the LLM.
What gpu.cpp is Not
gpu.cpp is meant for developers with some familiarity with C++ and GPU programming. It is not a high-level numerical computing or machine learning framework or inference engine, though it can be used in support of such implementations.
Second, in spite of the name, WebGPU has native implementations decoupled from the web and the browser. gpu.cpp leverages WebGPU as a portable native GPU API first and foremost, with the possibility of running in the browser being being a convenient additional benefit in the future.
If you find it counerintuitive, as many do, that WebGPU is a native technology and not just for the web, watch Elie Michel’s excellent talk “WebGPU is Not Just About the Web”.
Finally, the focus of gpu.cpp is general-purpose GPU computation rather than rendering/graphics on the GPU, although it can be useful for offline rendering or video processing use cases. We may explore directions with graphics in the future, but for now our focus is GPU compute.
Limitations and Current Work
API Improvements - gpu.cpp is a work-in-progress and there are many features and improvements to come. At this early stage, we expect the API design to evolve as we identify improvements / needs from use cases. In particular, the handling of structured parameters and asynchronous dispatch will undergo refinement and maturation in the short-term.
Browser Targets - In spite of using WebGPU we haven’t tested builds targeting the browser yet though this is a short-term priority.
Reusable Kernel Library - Currently the core library is strictly the operations and types for interfacing with the WebGPU API, with some specific use case example WGSL implementations in examples/. Over time, as kernel implementations mature we may migrate some of the reusable operations from specific examples into a small reusable kernel library.
More Use Case Examples and Tests - Expect an iteration loop of use cases to design tweaks and improvements, which in turn make the use cases cleaner and easier to write. One short term use cases to flesh out the kernels from llm.c in WebGPU form. As these mature into a reusable kernel library, we hope to help realize the potential for WebGPU compute in AI.
Closing Thoughts and Getting Involved
We welcome collaborators - if you’re interested in getting involved, feedback and pull requests are welcome at github.com/AnswerDotAI/gpu.cpp. You can also join our discord to chat at #gpu-cpp.
GPUs are arguably the most empowering technology in the world today. However, it can feel like the joy of creating and exploring ideas through GPU code has been somewhat elusive. Somewhere between having to write a 1000 lines of boilerplate to dispatch a small compute kernel and operationalizing a new algorithm where 99% of the effort is squeezing a small implementation into a massive tower of machine learning technology stacks, the tools around the technology get in the way so much that GPUs on personal devices are often underutilized.
gpu.cpp is a shared experiment to make low-level on-device GPU computation more productive and fun while enabling you to run GPU code anywhere and everywhere.