JaColBERTv2.5🇯🇵: Optimising Retrieval Training for Lower-Resources Languages
This is a short blog post, mainly geared towards an audience of Information Retrieval (IR) or IR-interested Natural Language Processing (NLP) practitioners.
We’re releasing 🇯🇵JaColBERTv2.5 and JaColBERTv2.4, the new state-of-the-art retrievers on all Japanese benchmarks.
Both of them largely outperform all existing previous Japanese retrieval models, including bge-m3. They do so with just 40% of the data used by JaColBERTv2, training for less than 15 hours on just 4 A100 GPUs!
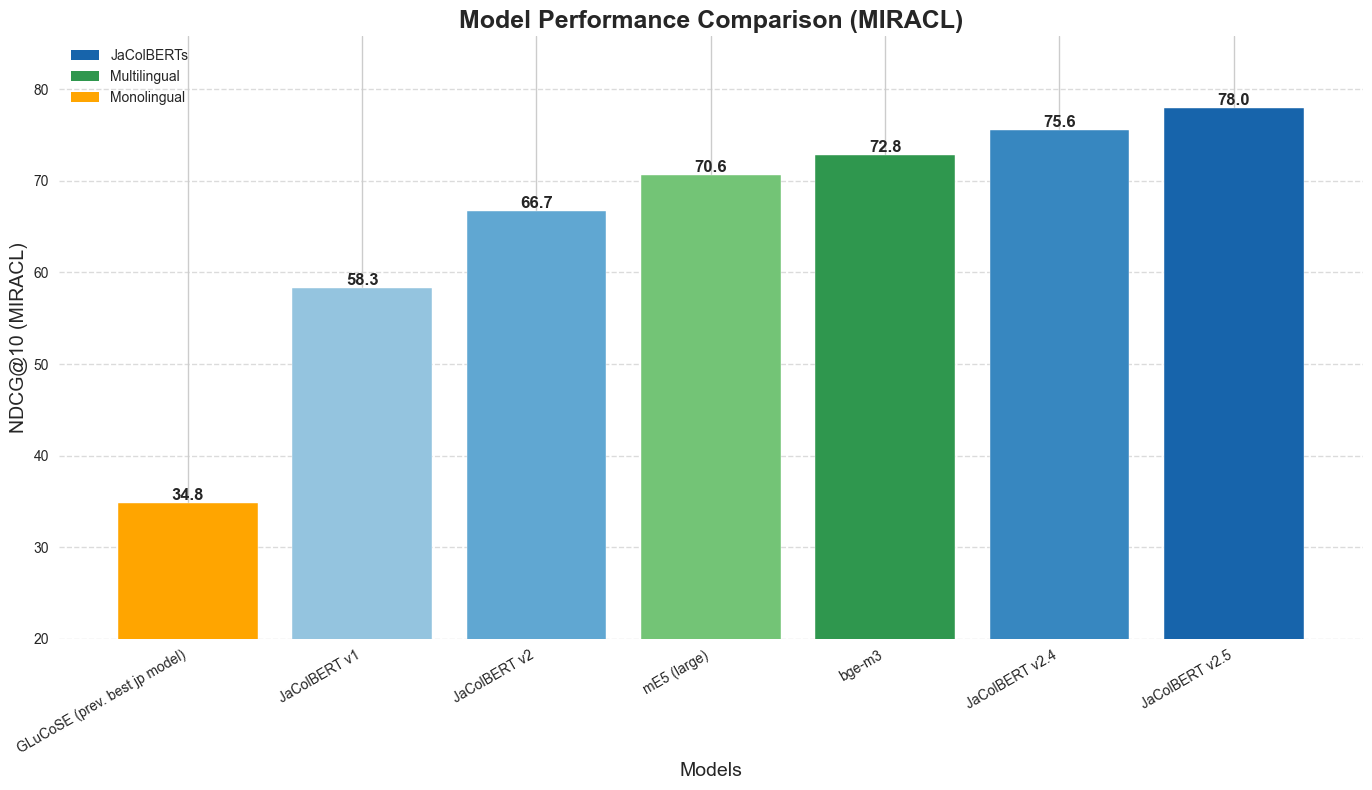
JaColBERTv2.4 is the result of being purely trained on MMarco, and is therefore truly out-of-domain to every downstream application task. The final model, JaColBERTv2.5, goes through an additional post-training task on higher quality Japanese retrieval datasets. Both models use averaged weights from multiple individual checkpoints.
It is the result of very thorough ablation runs (nearly 30 reported results!) to evaluate and solve various inefficiencies in the way ColBERT models are usually trained. The full experiments and their detailed results are explained and presented in the JaColBERT technical report.
To support further research in the area of multi-vector retrievers, we have made public:
- 🤗 JaColBERTv2.4: the model trained purely on MMarco
- 🤗 JaColBERTv2.5: the model trained purely on MMarco, and then post-trained on higher quality Japanese retrieval datasets
- 🤗 Our full training data, teacher scores for distillation included, for both all teacher ablations and the final training run!
- 🤗 Our training snapshots, with checkpoints saved every 2000 steps during the final training run.
Interested in a quick overview of how we achieved this? Read on!
Learning to Train a Multi-Vector Model
JaColBERTv2, the previous best Japanese-only model, was trained on 8 million triplets, taking about 20 hours on 8 A100s. It did a lot better than other Japanese-only models and was competitive with the best multilingual approaches, but it fell noticeably short of them on large-scale retrieval benchmarks.
JaColBERTv2.5, on the other hand, is trained on 3.2 million triplets (that’s 40% of the original data!), for 15 hours on 4 A100s. It outperforms all existing models on all benchmarks, at any evaluation scale, and with just 110M parameters.
So how did we achieve it? The training corpus hasn’t changed, except we use less of it. These results are all about the oh-so-unglamorous training optimizations.
Starting from the idea that there were clear potential inefficiencies to identify in the existing ColBERT training recipe, we ran ~28 ablations, to confirm (or infirm!) these intuitions.
Training & Inference Optimizations
Without providing a fully exhaustive listing (it’d be far too long, and you can find it in the paper), the key aspects are:
- Knowledge distillation from cross-encoders is immensely powerful.
- ColBERT-style query augmentation using the
[MASK]token matters a lot, and using a dynamic query length boosts performance. - In-batch negatives aren’t useful in training multi-vector models, and are very inefficient to compute memory-wise.
- Score normalization helps in ensuring your model learns to reproduce the teacher’s scores distribution, no matter the scale. You should min-max normalize both your student scores (ColBERT’s output) and your teacher scores.
- For ColBERT, KL-Div appears to be a strictly superior loss to MarginMSE (this is unlike SPLADE models, where KL-Div+MarginMSE mixed-loss is better).
- Schedule-free learning appears to work very well here, and is particularly well-suited to retrieval, where we want to be able to stop and restart training fairly often to match different data distributions.
- The choice of the teacher from which we distill matters immensely, but common English-language wisdom established on older models doesn’t necessarily apply to lower-resource, modern methods!
- Specifically, in our case, ensembling teachers does not outperform a single strong teacher in this lower-resource language context, going against the commonly held belief.
- Even more interesting: monolingual cross-encoders generating scores on translated versions of the same data result in very different downstream performance patterns (while reaching overall similar average scores).
Post-Training and Checkpoint Averaging
Traditionally, ColBERT models are evaluated only out-of-domain. This is fairly suboptimal, especially in the case of Japanese where the biggest training corpus is machine translated, with some rather odd language use at times.
Two-step training, involving an initial pre-training step on a large quantity of mixed-quality data (such as Japanese MMarco), followed by a second step on higher quality data, is growing increasingly popular in some domains, and works very well here.
We dub the model resulting from just the pre-training step JaColBERTv2.4, and further post-train the model on about 180k triplets, from higher quality datasets, including MIRACL, to create the building blocks for JaColBERTv2.5.
The building blocks? Yes, because we experience mild catastrophic forgetting, even when we re-inject from the original pre-training corpus! Our final model, which was better on average and much better at now-in-domain datasets, becomes slightly worse on the out-of-domain ones.
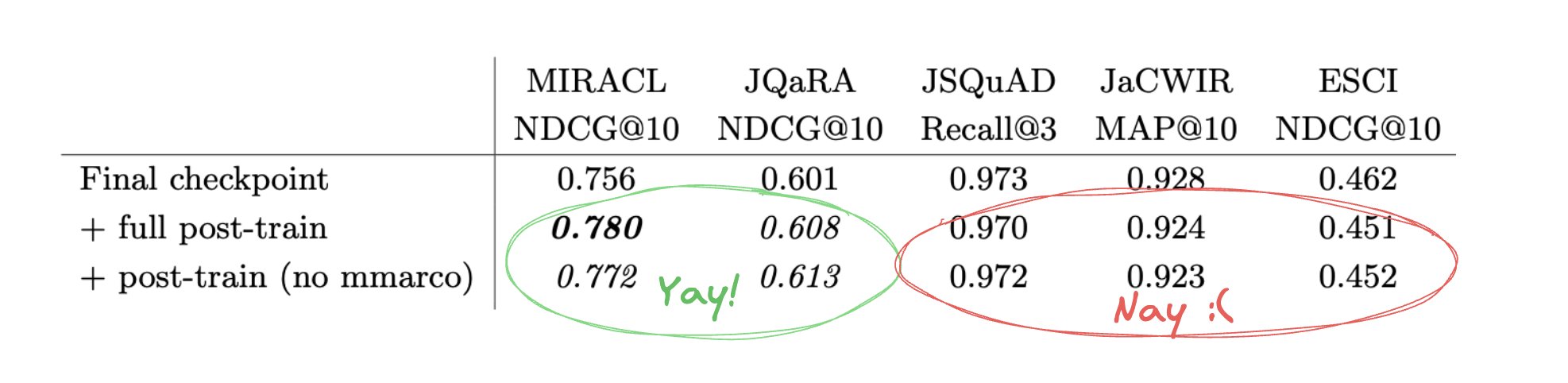
But there’s an easy way to fix this: What if we took the post-trained models, and just averaged their weights? This intuition, borrowed from Polyak’s views on the importance of averaging stochastic models, works even better than you’d expect: not only does it virtually completely erase the forgetting, it also increases performance on one of the two in-domain tasks!
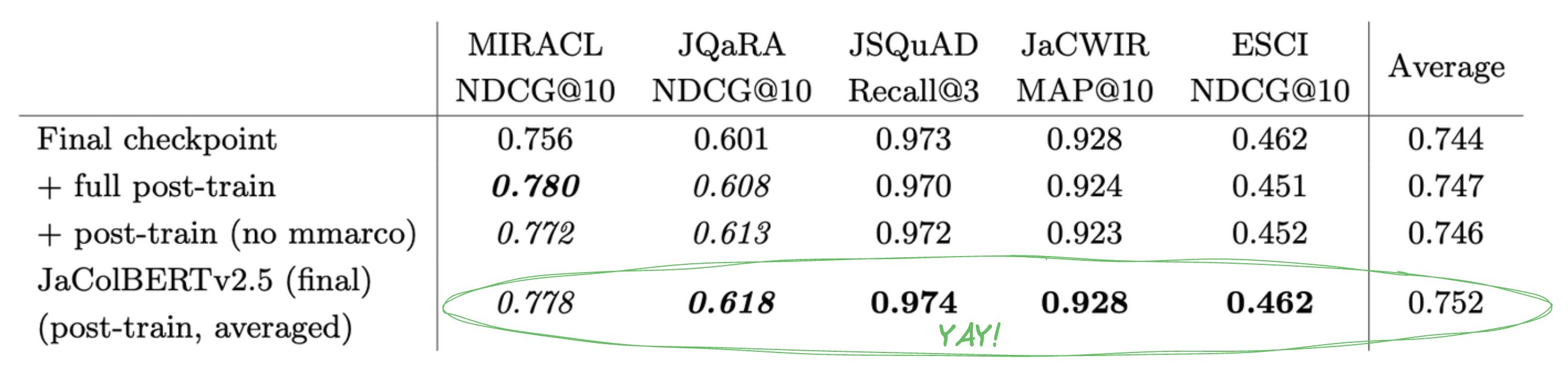
To achieve this, we simply averaged three of the best checkpoints from the pre-training with two post-trained models, one with and one without pre-training data re-injection.
Final Thoughts
There are definitely still a lot of training inefficiencies and programming quirks remaining in the multi-retrieval universe, but we think that these results highlight a very promising direction for future research.
Better understanding knowledge distillation is a great step towards being able to move past data scarcity and quality issues, especially in lower volume languages. This approach would likely work great with synthetic data, and we’re excited to see what the future holds in this area!
In the meantime, we’re also planning a complete overhaul of the RAGatouille library, to make these models even simpler to use in your own pipelines. Stay tuned 👀