TIL: Masked Language Models Are Surprisingly Capable Zero-Shot Learners
Welcome to this post! As a “TIL”, it’s a purposefully smaller blog post, containing just the key details. If you’d like to know more, head over to the technical report or play with the model on HuggingFace!
TL;DR
Traditionally (with some exceptions, of course), encoder models such as BERT are used with a task-specific head on top of the core encoder model. Functionally, this means that we discard all the language modelling goodness stored in the Masked Language Modelling head (the one used during pre-training), and seek to simply re-use the backbone to perform various tasks.
This works really well: there’s a reason why it’s the dominant paradigm! However, what if the generative head itself could actually perform most tasks, even zero-shot? This is what we tried, and it works pretty well! We introduce ModernBERT-Large-Instruct, an “instruction-tuned” encoder fine-tuned on top of ModernBERT-Large with a shockingly simple mechanism. It can be used to perform classification and multiple-choice tasks using ModernBERT’s MLM head instead of task-specific heads. Unlike previous approaches, our method requires no architectural changes nor complex pieplines, and still achieves strong results across various tasks.
- It’s surprisingly capable at knowledge QA tasks, where encoders are usually weak: On the MMLU-Pro leaderboard, it outperforms all sub-1B models like Qwen2.5-0.5B and SmolLM2-360M, and is quite close to Llama3-1B (trained on considerably more tokens, and with 3x the parameters)!
- On NLU tasks, fine-tuning ModernBERT-Instruct matches or outperforms traditional classification heads when fine-tuned on the same dataset.
- We achieve these results with a super simple training recipe, which is exciting: there’s definitely a lot of room for future improvements👀👀
I just want to try it!
The model is available on HuggingFace as ModernBERT-Large-Instruct. Since it doesn’t require any custom attention mask, or anything of the likes, the zero-shot pipeline is very simple to set up and use:
import torch
from transformers import AutoTokenizer, AutoModelForMaskedLM
# Load model and tokenizer
model_name = "answerdotai/ModernBERT-Large-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
if device == 'cuda':
model = AutoModelForMaskedLM.from_pretrained(model_name, attn_implementation="flash_attention_2")
else:
model = AutoModelForMaskedLM.from_pretrained(model_name)
model.to(device)
# Format input for classification or multiple choice. This is a random example from MMLU.
text = """You will be given a question and options. Select the right answer.
QUESTION: If (G, .) is a group such that (ab)^-1 = a^-1b^-1, for all a, b in G, then G is a/an
CHOICES:
- A: commutative semi group
- B: abelian group
- C: non-abelian group
- D: None of these
ANSWER: [unused0] [MASK]"""
# Get prediction
inputs = tokenizer(text, return_tensors="pt").to(device)
outputs = model(**inputs)
mask_idx = (inputs.input_ids == tokenizer.mask_token_id).nonzero()[0, 1]
pred_id = outputs.logits[0, mask_idx].argmax()
answer = tokenizer.decode(pred_id)
print(f"Predicted answer: {answer}") # Outputs: BFor more, you’ll want to check out our mini cookbook GitHub repository, with examples on how to fine-tune the model!
Introduction
Encoder models traditionnally perform best on all tasks with a task-specific head. While not necessarily an issue, this feels like a bit of a waste: the MLM head, its original pre-training head, is fully discarded. In practice, this works, but it also feels like we might leaving something on the table. Additionnally, this places great restrictions on zero-shot capabilities: as task-specific heads are usually always required, it’s been necessary to find various tricks to get around this and still get good zero-shot performance.
A brief, incomplete history of downstream uses of MLM encoders
Zero-shot classification with encoder models has been an active area of research, with various approaches tried over the years. The most common approach has been to repurpose textual entailment: after training on tasks like MNLI, models are used to predict whether a given label is entailed by the input text. Some very powerful models have been trained on the large-scale TaskSource datasets, such as tasksource/ModernBERT-large-nli.
This is also definitely not the first piece of work exploring generative BERTs as multitasks learners: there’s been some work on prompting, sample-efficient training via the pattern-exploitng training (PET) method, or even making the models auto-regressive! Some approaches are even pretty similar to ours, like UniMC which has shown promise by converting tasks into multiple-choice format using semantically neutral verbalizers (e.g., “A”, “B” instead of meaningful words) and employing custom attention masks.
However, all of these methods come with drawbacks: some are either brittle (particularly to different verbalizers) or reach performance that is promising-but-not-quite-there, while others yet reach very good results but add considerable complexity. Meanwhile, in decoder-land (or, if you will, LLMTopia), instruction tuning has progressed extremely rapidly, and big, scary LLMs have become very good at generative classification, especially zero-shot, thanks to their instruction training.
But this, too, has drawbacks: small LLMs are routinely outperformed by encoders, which can even match the larger ones once fine-tuned! Additionnally, the computational cost of running an autoregressive LLM, even one on the smaller side, is generally considerably bigger than that of an encoder, who performs tasks in a single forward pass.
ModernBERT-Large-Instruct
Our approach aims to show that maybe, just maybe, we can have our cake and eat it too: what if an MLM could tackle tasks (even zero-shot ones!) in a generative way with a single forward pass, could be easily fine-tuned further to perform better in-domain, without adding any pipeline or architectural complexity?
This is what we demonstrate the potential of here! We use a very simple training recipe, with FLAN-style instruction tuning with ModernBERT’s MLM head. We do not custom attention masks, no complex prompt engineering, and no heavy-handed data pre-processing pipeline: we simply filter FLAN to only tasks that can be answered using a single token, and filter out some examples from datasets that we used for downstream evaluations.
How It Works
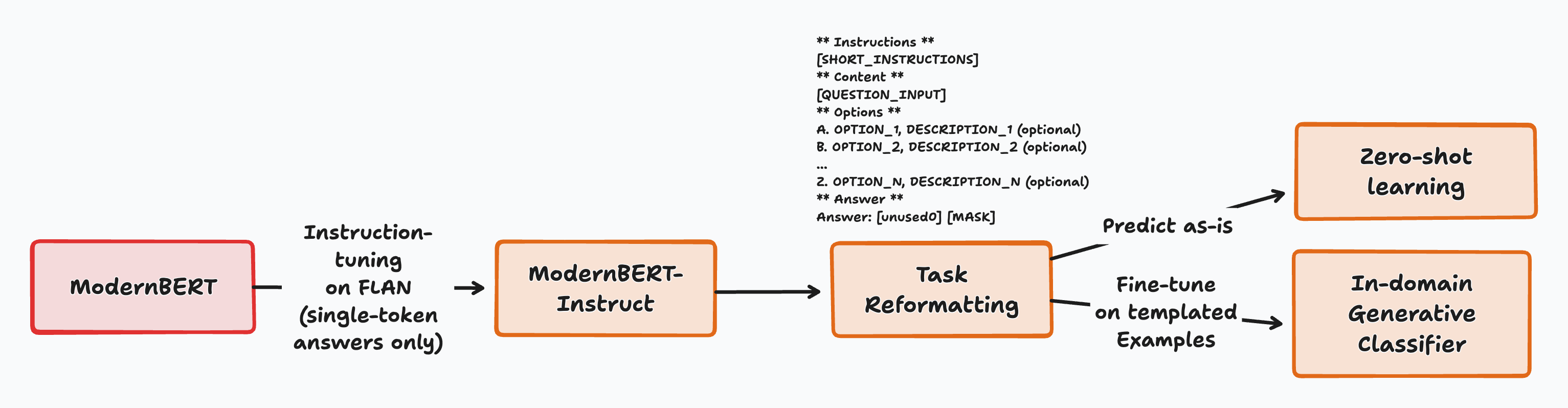
Our key insight is two-fold: ModernBERT can use a single-head to perform most NLU tasks, either zero-shot or fully-finetuned, and this behaviour can be unlocked with an extremely simple training recipe, suggesting a very strong potential.
The way it works is very simple:
- All tasks are formatted in a way where the model can answer with a single token, which is also the final token of the input. This is always prefaced with an anchor token (
[unused0]), to tell the model that the next token needs to be the single token answer. - The model is given a question, short instructions, and a list of potential choices. All choices are prefaced with a single-token verbalizer: this is the token that the model will predict if it assigns this label.
- The model then predicts the most likely token for the answer, and the potential verbalizer with the highest score is selected as the answer.
This approach has several advantages: - No architectural changes needed, for training or inference. - It can be tried on any model that supports Masked Language Modeling out of the box. - Very little data pre-processing is needed to begin experimenting. - Likewise, it reduces prompt engineering greatly: only a very short template and a description of all labels needs to be written to perform a task.
Training Details
As above, the training recipe is kept voluntarily simple. This is largely meant to avoid scope screep: there are a lot of potential improvements to be explored by using better processing pipelines, or more modern instruction sets, but these would all require complex processes to turn them into single-token tasks.
- Data: A downsampled (20M samples), filtered FLAN-2022 dataset to keep only single-token answers. A very simple filtering process: tokenize the potential answer and exclude all examples where the answer contains more than one token. Examples from our evaluation datasets were also filtered out to avoid overfitting.
- Objective: We use the Answer Token Prediction (ATP) objective, which is to predict the single masked token which should be the verbalizer containing the answer. The final training objective is a mix of 80% ATP and 20% dummy MLM examples, where masked tokens are given a meaningless label (see below).
- Base Model: ModernBERT-Large (395M parameters), which we recently introduced with our friends at LightOn & other places. It proved to be a much more capable base model than alternatives.
Dummy Examples
When training the model, we theorized that Answer Token Prediction could lead to catastrophic forgetting, with the model only learning to predict certain tokens and losing overall reasoning capabilities. To counter this, we introduced a training objective mix, where 20% of the examples were assigned the normal MLM objective (where 30% of tokens in the text are randomly masked, and the model has to predict all of them at once), with the remaining 80% adopting the Answer Token Prediction objective.
Except, we implemented this wrong, and effectively made these samples empty examples, which we dub “dummy MLM examples”. The issue was in the labelling: rather than the [MASK] tokens being assigned the appropriate label, they were all given [MASK] as their label. This meant that very quickly, the model learned to simply predict [MASK] for all of them if there’s more than one [MASK] token in the text, and the loss on these examples swiftly dropped to near-zero.
Hm, simple mistake, easy to fix, right? Right. Except, we observed something that we didn’t expect: we evaluated three pre-training setups (100% ATP, 80%ATP/20%MLM, 80%ATP/20%dummy), and we found that the dummy example variant was the best performing one, by a good margin! While we haven’t explored this phenomenon in enough depth to explain what is going on, my personal theory is that it acts as a form of regularization, similar to dropout.
Performance
Zero-Shot Results
The zero-shot results are pretty encouraging and, in a way, pretty surprising!
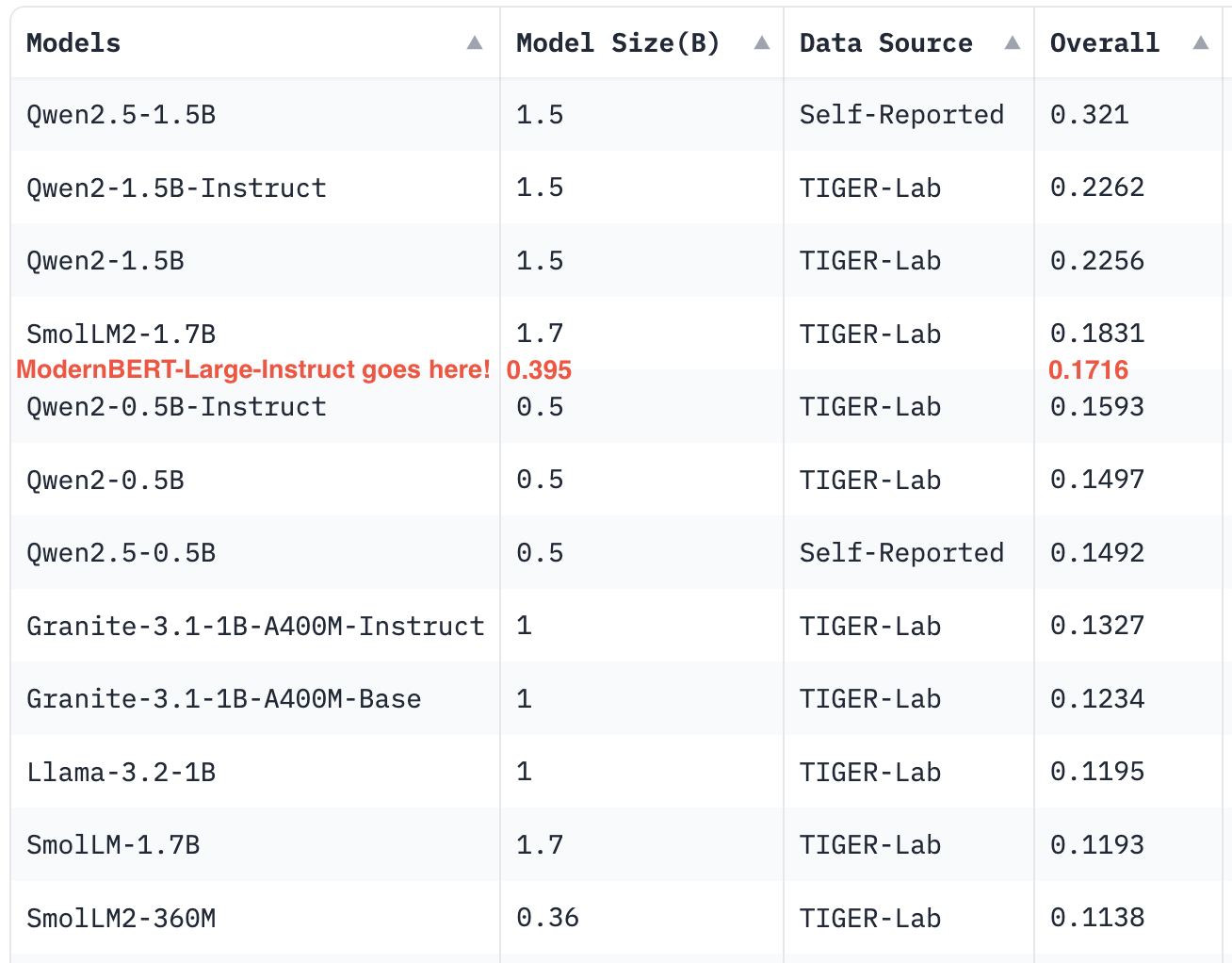
- Knowledge-Based Multiple Choice Questions (MMLU and MMLU-Pro): ModernBERT-Large-Instruct stands at 43.06% accuracy on MMLU, beating similarly sized models like SmoLLM2-360M (35.8%) and getting close to Llama3-1B (45.83%). On MMLU-Pro, its performance would give it a very good spot on the leaderboard, punching far above its weight class and competing with bigger LLMs!
- Classification: On average, it beats all the previous zero-shot methods. However, this is not true on a per-dataset basis: while this method has strong potential and gets very good overall results, there are some datasets where it underperforms, and others where it overperforms. This indicates strong potential for future developments of the method.
Fine-Tuned Results
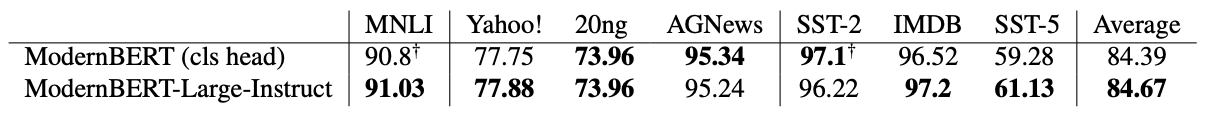
Across a variety of tasks, focusing on topic classification, textual entailment (MNLI) and sentiment analysis, fine-tuning ModernBERT-Large-Instruct on each task appears to match the performance of traditional classification head-based approach. On certain datasets, it even outperforms them! In fact, I think that this method holds the key to finally closing the last gap and making ModernBERT a better classifier than DeBERTaV3.
A caveat here is that the training set of some of these tasks is present, in relatively small proportions, in our pre-training mix: however, we expect this effect to be rather minimal, as fine-tuning performed for multiple epochs bring both methods firmly into the “in-domain” territory.
Modernity Matters

Finally, we wanted to know whether this potential is inherent to all pre-trained MLM encoders, or whether it’s specific to ModernBERT. To answer this question, we applied the same approach to older models like RoBERTa-Large or models with a modern architecture but trained on smaller-scale, less diverse data, and the performance dropped significantly:
| Model | MMLU |
|---|---|
| ModernBERT-Large-Instruct | 43.06 |
| GTE-en-MLM-Large | 36.69 |
| RoBERTa-Large | 33.11 |
This suggests that strong generative downstream performance in MLM encoders relies largely on being trained on a sufficiently large-scale, diverse data mix, given the vast performance gap between ModernBERT-Large-Instruct and GTE-en-MLM-Large, which adopts a very similar architecture to that of ModernBERT-Large (minus efficiency tweaks). The relatively smaller performance gain from RoBERTa-Large to GTE-en-MLM-Large seems to suggest that while adopting a better architecutre does play a role, it is much more modest than that of the training data.
Looking Forward
While these results are promising, they are very early stage! All they really do is demonstrate the potential of the MLM head as a multi-task head, but they are far from pushing it to its limits. Among other things:
- Exploring better, more diverse templating
- A more in-depth analysis of the training mechanisms, and the effect of dummy examples
- Testing on more recent instruction datasets, with better construction
- Investigating few-shot learning capabilities
- Scaling to larger model sizes
- … so many more things!
All strike us as very promising directions for future work! In fact, we’ve heard that some very good people are working on some of these things already…
Ultimately, we believe that the results of our exceedingly simple approach presented here open up new possibilities for encoder models. The ModernBERT-Large-Instruct model is available on HuggingFace.